您现在的位置是:网站首页>编程语言
怎么撸一个m3u8视频下载程序(基础篇)
【编程语言】阿文2020年3月12日1387浏览
简介作为一枚码农怎么能放弃自己的技能去手动操作,于是前几天撸了一个关于m3u8视频文件爬取的demo,由于本人主要用C#作为主要开发语言,顺手就用了C#写了这个demo,其实程序得实现原理大多共通的,其他语言也可以按照这个逻辑去实现。本demo主要针对未加密、未鉴……
最近一段时间在家办公忙于工作上的事情加上其他原因,至于文章更新停了一段时间,主要自己太懒了,之前写的两篇文章《怎么下载视频网站的视频?》、《cmd命令行无损合并批处理TS视频文件》主要写了点怎么去分析网页上视频的路径和手动操作下载好的m3u8视频片段合并的方法。但是作为一枚码农怎么能放弃自己的技能去手动操作,于是
前几天撸了一个关于m3u8视频文件爬取的demo, 由于本人主要用C#作为主要开发语言,顺手就用了C#写了这个demo,其实程序得实现原理大多共通的,其他语言也可以按照这个逻辑去实现。本demo主要针对未加密、未鉴权的视频,关于加密的视频和带鉴权的链接会在后面的提升篇中慢慢讲到。
大概流程图:
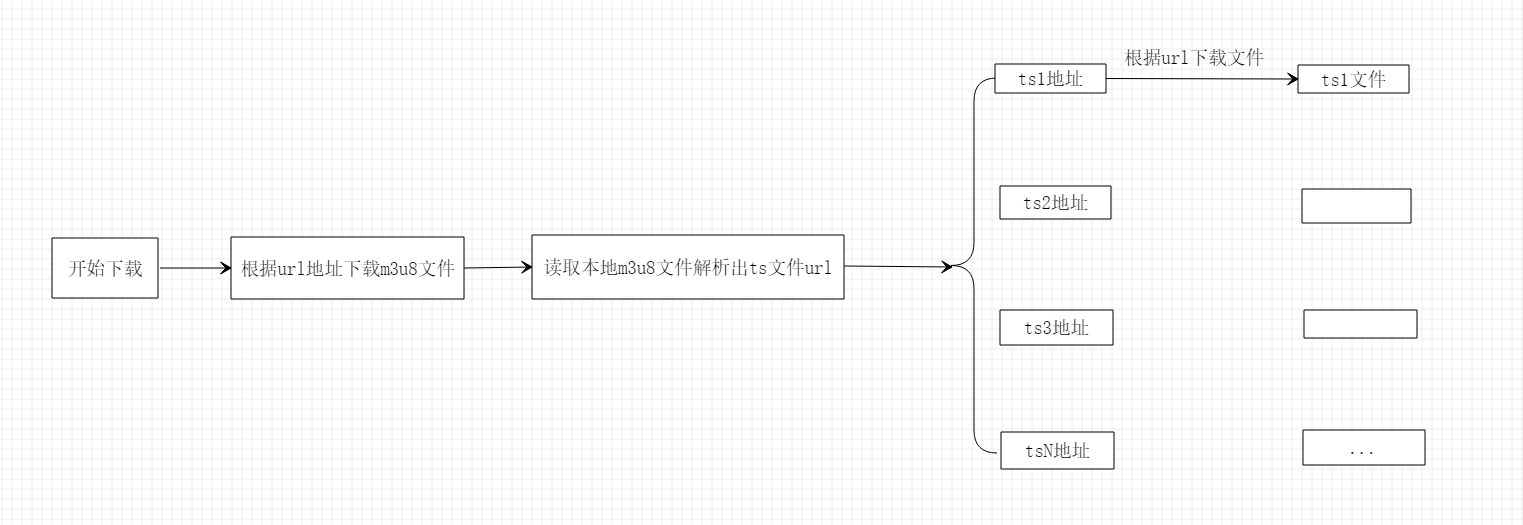
一、首先我们先明确要下载的视频m3u8地址
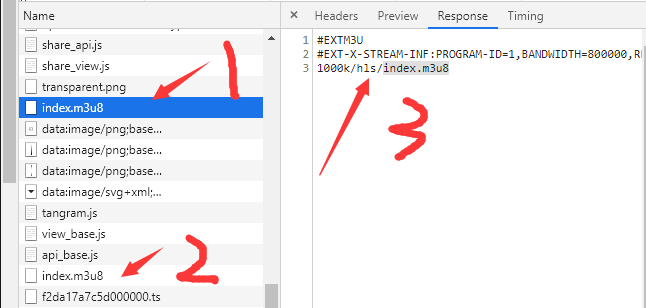
这一步在某些网站上有点坑,一个视频页面会有两个m3u8地址,其中一个可能是页面占位用或者是广告之类的,我们可以点击页面播放按钮来确定视频的真实m3u8文件地址。 如下图位置1的m3u8结尾的文件就不是一个真实m3u8文件地址,具体可以看位置3的内容,位置2的m3u8文件才是真实的视频地址,具体怎么看就看右边response输出来判断,看里面是否包含.ts文件,ts个数是否合理,一般网站的ts切片大多5s-10s一个,一个10分钟的视频ts切片不少。ts切片比较的m3u8文件可能是广告。
二、撸代码实现
第一步.明确我们下载文件保存路径,我这里设置的是程序启动目录下download文件夹
/// <summary>
/// 保存目录
/// </summary>
string basesavepath = AppDomain.CurrentDomain.BaseDirectory + @"download"; 第二步.下载m3u8文件,我们把同一个视频的m3u8文件和ts文件放在一个文件夹目录下面
var m3u8url = "https://xxx.com/20191115/15103_102f5c73/1000k/hls/index.m3u8"; //m3u8文件地址
var xdirname = "xxxxx";//保存当前视频的文件夹名称
var savesoucepath = basesavepath + @"/souce"; //原始文件目录
var filesavedic = savesoucepath + @"/" + xdirname; //文件保存的最终目录
//判断文件夹是否存在,不存在就创建
if (!Directory.Exists(savesoucepath + @"/" + xdirname))
Directory.CreateDirectory(savesoucepath + @"/" + xdirname);
//获取m3u8的文件名
var m3u8filename = m3u8url.Substring(m3u8url.LastIndexOf('/') + 1);
if (!DownloadFile(m3u8url, filesavedic + @"/" + m3u8filename))
{
//Log.Error("下载m3u8文件失败:" + m3u8url);
Console.WriteLine("下载m3u8文件失败:" + m3u8url);
}第三步.解析m3u8文件得到ts文件的地址列表并逐个下载
//当前m3u8文件存放的路径
var m3u8filepath = filesavedic + @"/" + m3u8filename;
//当前m3u8文件相对url 一般m3u8文件中ts文件不带url路径,我们需要拿到相对url来拼接 如 https://xxx.com/20191115/15103_102f5c73/1000k/hls/
var m3u8baseurl = m3u8url.Substring(0, m3u8url.LastIndexOf('/') + 1);
//按行读取m3u8文件
var list = File.ReadAllLines(m3u8filepath, Encoding.UTF8);
foreach (var item in list)
{
//判断.ts结尾的行
if (item.Length > 0 && item.EndsWith(".ts"))
{
//ts文件保存路径
var tsfilepath = filesavedic + @"/" + item;
//ts文件下载路径
var tsurl = m3u8baseurl + @"/" + item;
//判断ts路径是否带url路径,如果带的话则用ts本身路径
if (item.ToLower().StartsWith("http"))
{
tsfilepath = filesavedic + @"/" + item.Substring(item.LastIndexOf('/') + 1);
tsurl = item;
}
//下载ts文件
if (!DownloadFile(tsurl, tsfilepath))
{
Console.WriteLine("下载ts文件失败:" + tsurl);
}
}
System.Threading.Thread.Sleep(100);
}以上就是下载一个m3u8视频文件关键步骤, 完整代码在下面
using System;
using System.IO;
using System.Net;
using System.Text;
namespace DownLoadDemo
{
class Program
{
static void Main(string[] args)
{
string basesavepath = AppDomain.CurrentDomain.BaseDirectory + @"download";
var m3u8url = "https://xxx.com/20191115/15103_102f5c73/1000k/hls/index.m3u8"; //m3u8文件地址
var xdirname = "xxxxx";//保存当前视频的文件夹名称
var savesoucepath = basesavepath + @"/souce"; //原始文件目录
var filesavedic = savesoucepath + @"/" + xdirname; //文件保存的最终目录
//判断文件夹是否存在,不存在就创建
if (!Directory.Exists(savesoucepath + @"/" + xdirname))
Directory.CreateDirectory(savesoucepath + @"/" + xdirname);
//获取m3u8的文件名
var m3u8filename = m3u8url.Substring(m3u8url.LastIndexOf('/') + 1);
if (!DownloadFile(m3u8url, filesavedic + @"/" + m3u8filename))
{
//Log.Error("下载m3u8文件失败:" + m3u8url);
Console.WriteLine("下载m3u8文件失败:" + m3u8url);
}
//当前m3u8文件存放的路径
var m3u8filepath = filesavedic + @"/" + m3u8filename;
//当前m3u8文件相对url 一般m3u8文件中ts文件不带url路径,我们需要拿到相对url来拼接 如 https://xxx.com/20191115/15103_102f5c73/1000k/hls/
var m3u8baseurl = m3u8url.Substring(0, m3u8url.LastIndexOf('/') + 1);
//按行读取m3u8文件
var list = File.ReadAllLines(m3u8filepath, Encoding.UTF8);
foreach (var item in list)
{
//判断.ts结尾的行
if (item.Length > 0 && item.EndsWith(".ts"))
{
//ts文件保存路径
var tsfilepath = filesavedic + @"/" + item;
//ts文件下载路径
var tsurl = m3u8baseurl + @"/" + item;
//判断ts路径是否带url路径,如果带的话则用ts本身路径
if (item.ToLower().StartsWith("http"))
{
tsfilepath = filesavedic + @"/" + item.Substring(item.LastIndexOf('/') + 1);
tsurl = item;
}
//下载ts文件
if (!DownloadFile(tsurl, tsfilepath))
{
Console.WriteLine("下载ts文件失败:" + tsurl);
}
}
System.Threading.Thread.Sleep(100);//暂停100毫秒 防止同一ip下载请求过多被屏蔽
}
}
private static bool DownloadFile(string url, string filepath)
{
try
{
FileStream fs = new FileStream(filepath, FileMode.Create, FileAccess.Write, FileShare.Delete);
// 设置参数
HttpWebRequest request = WebRequest.Create(url) as HttpWebRequest;
//发送请求并获取相应回应数据
HttpWebResponse response = request.GetResponse() as HttpWebResponse;
//直到request.GetResponse()程序才开始向目标网页发送Post请求
Stream responseStream = response.GetResponseStream();
//创建本地文件写入流
//Stream stream = new FileStream(tempFile, FileMode.Create);
byte[] bArr = new byte[1024];
int size = responseStream.Read(bArr, 0, (int)bArr.Length);
while (size > 0)
{
//stream.Write(bArr, 0, size);
fs.Write(bArr, 0, size);
size = responseStream.Read(bArr, 0, (int)bArr.Length);
}
//stream.Close();
fs.Close();
responseStream.Close();
return true;
}
catch (Exception ex)
{
//Log.Error("下载文件" + url + "报错:" + ex);
return false;
}
}
}
}这只是一个简单的下载的demo逻辑,可能有人问我为什么不用多线程之类的,我这里只是写一下基础的下载逻辑,像多线程之类的后面写,其次多线程爬取的话速度太快容易被一些网站屏蔽IP,后面会增加优化篇。《怎么撸一个m3u8视频下载程序(提升篇)》
本文中的代码只用于借鉴和学习交流使用,用作他途本人概不负责
上一篇: 消息队列的使用场景大概是怎样的?
下一篇: 怎么撸一个m3u8视频下载程序(提升篇)









评论文明上网,理性发言0条评论